

مدیرمحصول! عاشق علوم داده و محاسبات کوانتومی
شناسایی ناهنجاری به کمک جنگل ایزوله؛ زیر میز بزنید!

با گسترش فناوریهای انفورماتیک، دامنهٔ فعالیت مدیران محصول نیز روز به روز توسعه و تنوع بیشتری مییابد. امروزه در اکثر شرکتهای مطرح نرمافزاری و تحلیل داده بهخصوص آنهایی که محصولات لبهٔ علم تولید میکنند، موقعیت شغلی AI/ML Product Manager و Data Product Manager ایجاد شده است و این افراد به صورت مستقیم بر فرایندهای یادگیری ماشین و هوش مصنوعی موجود در توسعهٔ محصول نظارت دارند. در این مقاله قصد داریم کمی در علوم داده عمیقتر شویم و با یک الگوریتم نسبتا جدید و کاربردی در زمینهٔ شناسایی دادههای پرت و ناهنجار آشنا شویم.
در تحلیلهای آماری شناسایی ناهنجاریها و یافتن نقاط پرت (Outlier Points) اهمیت بسیار زیادی دارد. در بعضی موارد وجود این نقاط باعث ایجاد خطا در طراحی مدل آماری شده و دقت پیشبینی انجام شده را به طرز محسوسی کاهش میدهد. مواردی نیز وجود دارد که این نقاط نشانگر بروز نفوذ و فعالیت غیرعادی کاربران است که با بررسی آن میتوان امنیت سیستم را افزایش داد.
در علم آمار، ناهنجاری یک مشاهدهٔ نامتعارف، رویداد یا مقداری است که اختلاف و انحراف قابل توجهی نسبت به سایر مقادیر و رفتار متفاوتی نسبت به دیگر نقاط داشته باشد. به طور مثال در میان توپهای غمگین، یک توپ خوشحال یک مشاهدهٔ ناهنجار و نامتعارف به حساب میآید.

نقاط ناهنجار میتوانند معانی متفاوتی داشته باشند. به طور مثال نمودار زیر نشاندهندهٔ ترافیک ورودی یک وبسایت است که بر اساس تعداد درخواستها در بازهی زمانی سه ساعته در مدت زمان یک ماه به تصویر کشیده است.
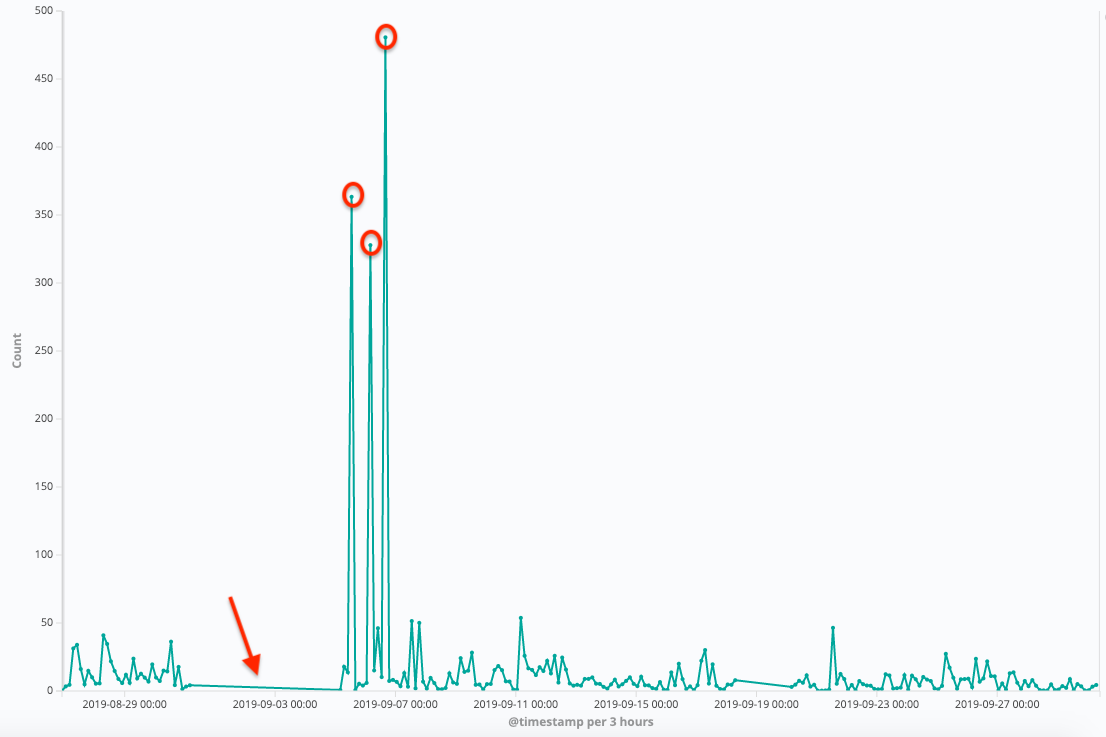
در نگاه اول کاملا مشخص است که برخی از نقاط (دور آنها دایره قرمز کشیده شده است) به طور غیرمعمولی بزرگتر از دیگر مقادیر هستند. یعنی در آن بازهٔ زمانی درخواستهایی که سمت سرور وبسایت ارسال شده، افزایش قابل توجهی داشته است. با توجه به اینکه این درخواستها به شکل مقطعی هستند و در زیر خود سطح تشکیل ندادهاند، اینطور به نظر میرسد که سرور در آن زمان مورد حمله DDos (حمله محرومسازی از سرویس) قرار گرفته است. البته حالتهای احتمالاتی دیگری نظیر وجود جشنوارههای فروش ویژه و ... را نیز میتوان در نظر گرفت که موجب شده در یک مدت زمان اندک تعداد زیادی درخواست ارسال شود. همچنین قسمت مسطح این نمودار نیز احتمالا نشانهی وجود اشکال و اختلال در عملکرد سرور است؛ چراکه در آن بازهٔ زمانی هیچ درخواستی دریافت نشده است.
بدیهی است که شناسایی ناهنجاریها و نقاط پرت تمام مجموعههای داده به همین سادگی امکانپذیر نیست و در مواردی، بهخصوص زمانی که با مجموعههایی از جنس کلانداده روبهرو هستیم، شناسایی نقاط پرت کار بسیار پیچیدهای است و نیازمند استفاده از الگوریتمهای هوشمند است.
روشهای آماری متعددی برای شناسایی ناهنجاریها وجود دارد که در این مقاله به بررسی الگوریتم جنگل ایزوله (Isolation Forest Algorithm) میپردازیم که یکی از بهروزترین و کاربردیترین الگوریتمهای علوم داده در حوزهٔ شناسایی ناهنجاریها و یافتن نقاط پرت است.
پیدایش الگوریتم جنگل ایزوله
در سال ۲۰۰۸ سه دانشمند علوم کامپیوتر به نامهای «فی تونی لیو»، «کای مینگ تینگ» و «ژوی هوآ ژو» برای اولین بار الگوریتم جنگل ایزوله (به اختصار iForest) را ابداع کردند. ایدهی اصلی آنها برای طراحی این الگوریتم دو ویژگی متداول دادههای پرت و ناهنجار بود که عبارتند از:
- کم بودن تعداد این نقاط نسبت به سایر نقاط
- تفاوت چشمگیر مقادیر این نقاط نسبت به تودهی کلی (هنجار) دادهها
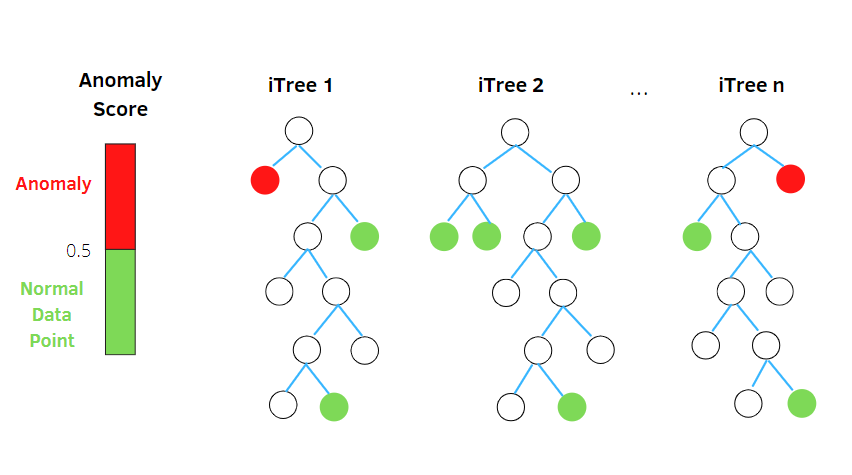
از آنجایی که ناهنجاریها تعدادشان کم و مقادیرشان متفاوت است، جداسازی و دستهبندی آنها در مقایسه با نقاط هنجار آسانتر است. راهکار کلی الگوریتم جنگل ایزوله این است که گروههایی از «درختان جداسازی» (Isolation Trees) در مجموعهی داده ایجاد کند. بدین ترتیب ناهنجاریها نقاطی هستند که بهطور میانگین مسیر کوتاهتری نسبت به دیگر نقاط در «درختان جداسازی» دارند. لازم به ذکر است که نویسندگان مقاله «درختان جداسازی» را به اختصار iTrees و الگوریتم جنگل ایزوله را iForest نامگذاری کردهاند.
در سال ۲۰۱۰ افزونهای از این الگوریتم به نام SCiforest با تمرکز بر بررسی مباحث ناهنجاریهای خوشهای و به کارگیری از اَبرصفحههای تصادفی به منظور افزایش توانایی تشخیص ناهنجاریهای موازی منتشر شد. این توانمندیها در نسخهٔ اولیه این الگوریتم وجود نداشت. کمی بعدتر در سال ۲۰۱۲ نویسندگان نسخهٔ اولیه مقاله «الگوریتم جنگل ایزوله» مجموعهای از آزمایشها را طراحی کردند تا ثابت کنند iForest دارای ویژگیهای زیر است:
- پیچیدگی زمانی اندکی دارد و برای اجرا شدن حافظهٔ کمی از دستگاه را اشغال میکند.
- قابل استفاده در دادههای بزرگ با ویژگیهای غیرمرتبط است.
- الگوریتم قابلیت یادگیری و آموزش را دارد.
- بدون نیاز به آموزش مجدد، توانایی ارائهٔ نتایج تشخیص با سطوح مختلف دستهبندی را دارد.
در سال ۲۰۱۳ دو دانشمند علوم کامپیوتر به نام «ژینگو دینگ» و «مینوری فی» ساختاری را بر مبنای iForest طراحی کردند که در آن مشکل تشخیص ناهنجاریها در جریان دادهها (streaming data) برطرف شده بود. این اتفاق نقطهٔ عطفی در توسعهٔ الگوریتم iForest به حساب میآمد، چرا که اکنون بسیاری از سیستمهای کلاندادهای نیز میتوانستند از این الگوریتم برای شناسایی نقاط ناهنجار و پرت استفاده کنند و همین امر سرعت انجام تحلیلهای آتی این جنس از دادهها و انجام فعالیتهایی نظیر «داده کاوی» و «یادگیری ماشین» را به طور محسوسی افزایش میداد.
زیر میز بزنید!
احتمالا انسانها پیش از آن که با مفهومی به نام علوم داده و تحلیلهای آماری آشنا شوند، به صورت ناخودآگاه الگوسازی از نقاط هنجار را انجام میدادند. متداولترین شیوهای که برای شناسایی نقاط ناهنجاری استفاده میشود استفاده از الگوریتم الگوسازی (Profiling) است. در این شیوه الگوریتم با تحلیل تمام اعضای مجموعهٔ داده، یک الگو از نقاط عادی میسازد و دادههایی که تفاوت معناداری با نقاط عادی دارند را به عنوان نقاط پرت و ناهنجار شناسایی میکند. این در حالی است که الگوریتم جنگل ایزوله یا همان iForest با شیوهی متفاوتی اینگونه نقاط را مورد شناسایی و بررسی قرار میدهد.
الگوریتم iForest به جای آنکه برای ساختن یک مدل نرمال تلاش کند، ابتدا نقاط غیرعادی و ناهنجار را شناسایی و از مجموعهٔ داده جدا میکند. این الگوریتم در ابتدا یک ویژگی (یک بُعد) را به صورت تصادفی انتخاب میکند و سپس یک مقدار تصادفی در فاصلهٔ بین کمینه و بیشینهٔ مجموعهٔ داده انتخاب کرده و با یک خط جداساز آن بُعد را جدا میکند. بدین ترتیب یک مجموعهٔ درخت ایجاد میشود و درختهایی که طول کمتری دارند به عنوان دادهٔ پرت و ناهنجاری شناسایی میشوند. لازم به ذکر است که iForest یک الگوریتم یادگیری بدون نظارت (Unsupervised Learning) به حساب میآید. در بخش بعدی مقاله با نحوهٔ فعالیت این الگوریتم بیشتر آشنا خواهیم شد.
جنگل ایزوله زیر ذرهبین
همان طور که در بخش قبلی اشاره شد، رهیافت متداول در شناسایی ناهنجاری، الگوسازی از نقاط نرمال بود؛ اما iForest رویکرد متفاوتی را در پیش گرفته است. ایدهی اصلی الگوریتم این است که اگر بر روی مجموعهٔ داده یک درخت تصمیمگیری رسم شود، نقاط ناهنجاری طول کوتاهتری دارند و به ریشه نزدیکتر هستند.
برای فهم بهتر این مفهوم با یک مثال ساده شروع میکنیم؛ حدودا نزدیک به ۸ میلیارد انسان بر روی کرهٔ زمین وجود دارند و آنها را به عنوان یک مجموعهٔ داده در نظر میگیریم. این مجموعهٔ داده را میتوان به بُعدهایی نظیر سن، دارایی، محل تولد، موقعیت شغلی و ... تقسیمبندی کرد. حال میخواهیم در این مجموعهی داده نقاط ناهنجار را شناسایی کنیم. دقت کنید که نقاط ناهنجار لزوما دادههای اشتباهی نیستند و تنها تفاوتی معنادار با دیگر نقاط دارند. رسم درخت تصمیمگیری را با بُعد «برخورداری از دارایی ۱۷۰ میلیارد دلاری» آغاز میکنیم.
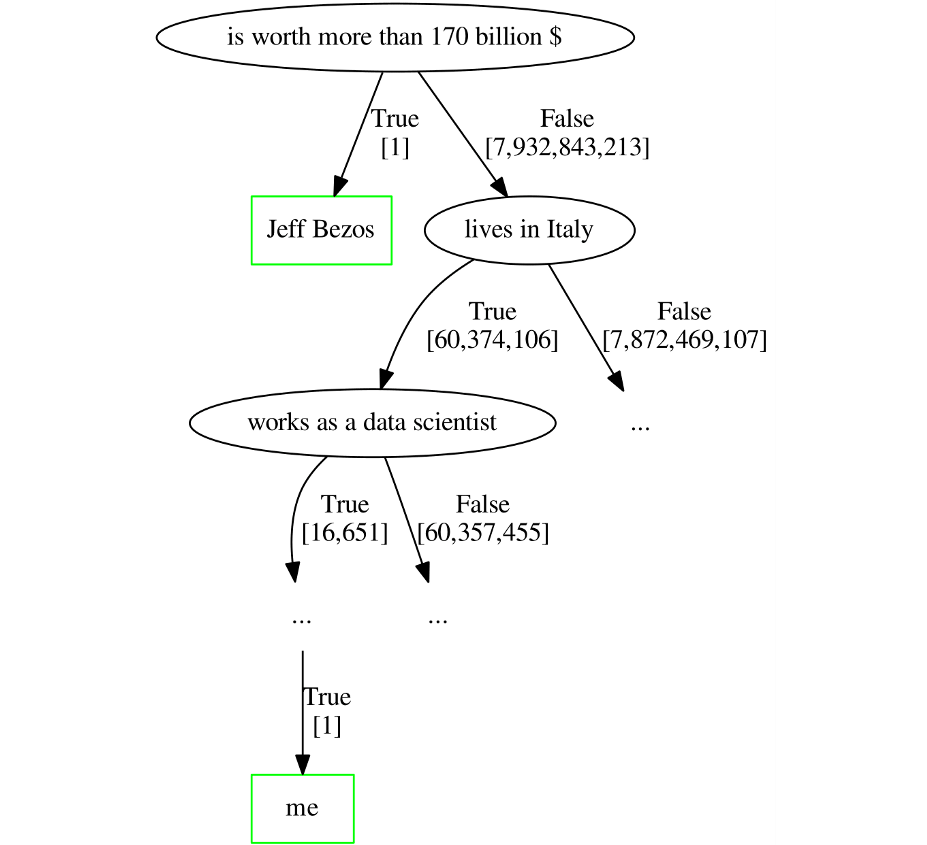
در این درخت تصمیمگیری «جف بزوس» بنیانگذار شرکت آمازون به عنوان یک نقطهٔ نامتعارف شناسایی می شود. با توجه به شکل مشخص است که او به ریشهٔ درخت بسیار نزدیک است. البته که این درخت تصمیمگیری هرس نشده است و احتمالا نقاط ناهنجاری دیگری نیز دارد.
برای ایزوله کردن درخت جف بزوس، تنها کافی است این سوال را بپرسید که «آیا او بیش از ۱۷۰ میلیارد دلار دارایی دارد؟» اما از آن جایی که شخص جلیل علیزاده (نویسندهٔ مقاله) بسیار معمولیتر از جف بزوس است، برای ایزوله کردن او حداقل نیاز به پرسیدن ۱۰ سوال بله/خیر دارید.
حال بهتر است به سراغ یک مثال آماریتر برویم و مجموعهای از دادهها را در مختصات دو بعدی x-y قرار بدهیم. این مجموعه داده را ابتدا از طریق یک بُعد (خط آبی) جداسازی میکنیم، سپس جداسازی با بُعد دوم (خط نارنجی) صورت میگیرد و در نهایت آخرین جداسازی (خط سبز) انجام میشود.
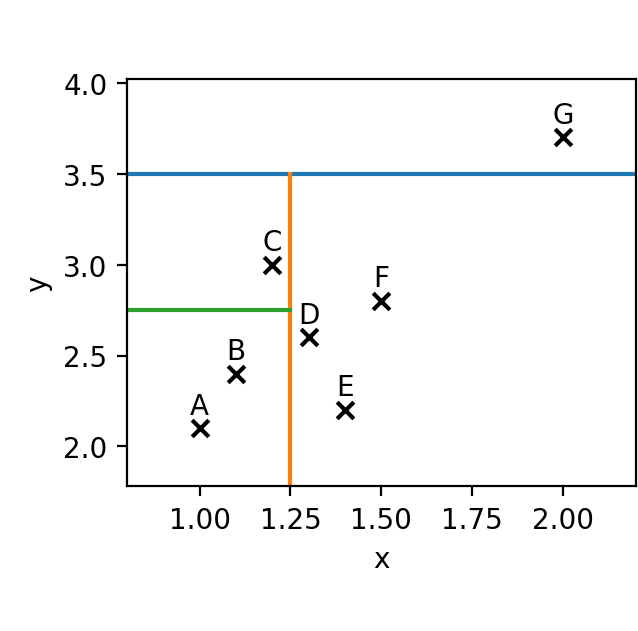
اگر بخواهیم این مجموعهٔ داده را به صورت درخت تصمیمگیری رسم کنیم، شکل زیر حاصل میشود. همانطور که مشخص است نقطهٔ G کوتاهترین طول مسیر (طول مسیر برابر ۱) را دارد و از همه نقاط دیگر به ریشه نزدیکتر است و به همین منظور نقطهٔ G یک ناهنجاری و داده پرت به حساب میآید. در این شکل به طور مثال نقطهٔ C طول مسیرش برابر ۳ است و بنابراین ناهنجاری نیست.

برای تولید یک جنگل ایزوله باید تعداد زیادی درخت ساخته شود و هر درخت مشخص میکند که کدام نقاط زودتر ایزوله میشوند که در حقیقت نقاط ناهنجار هستند. در نهایت پس از رسم درختها به هر نقطه یک امتیاز بین ۰ تا ۱ داده میشود.، هر میزان امتیاز ناهنجاری به ۱ نزدیکتر باشد، این نقطه به احتمال بیشتری یک دادهٔ پرت و ناهنجار است. در بحث بعدی به صورت متمرکزتر به بررسی نحوهٔ محاسبهٔ نمره ناهنجاری میپردازیم.
ویژگیهای اصلی جنگل ایزوله
اکنون نگاهی به ویژگیهای کلی iForest میاندازیم و نکات مثبت و منفی آن را مورد بررسی قرار میدهیم:
زیرنمونهگیری (Sub-sampling): با توجه به اینکه الگوریتم iForest نیازی به یافتن و جداسازی همهٔ نقاط نرمال ندارد، این الگوریتم میتواند تودهی عظیمی از نقاط نمونهی آموزشی را نادیده بگیرد. بنابراین میتوان ادعا کرد که iForest هنگامی که اندازهٔ نمونه کوچک نگه داشته شود، عملکرد بسیار خوب و دقت بالایی دارد. این ویژگی در میان دیگر الگوریتمها کمتر دیده میشود.
غرق شدن(Swamping): هنگامی که فاصلهٔ میان نقاط نرمال و نقاط ناهنجار بسیار کم باشد، تعداد درختهای موردنیاز برای جداسازی ناهنجاریها افزایش مییابد. در این شرایط ممکن است پدیدهای به نام «غرق شدن» رخ دهد. این امر سبب میشود که iForest تفاوت میان نقاط ناهنجار و نرمال را به کندی و با اشتباه فراوان تشخیص دهد. بنابراین ممکن است با هر بار اجرای الگوریتم، نقاط متفاوتی به عنوان ناهنجاری شناسایی شوند و همین امر باعث میشود تا دقت الگوریتم به طرز محسوسی کاهش پیدا کند.
پوشیده ماندن(Masking): زمانی که تعداد ناهنجاریها زیاد باشد، این احتمال وجود دارد که برخی از نقاط در یک خوشه متراکم و بزرگ قرار بگیرند و جداسازی ناهنجاریها توسط iForest بسیار سخت و دشوار شود. این امر شباهتهای زیادی با پدیدهٔ «غرق شدن» دارد و با انجام کارهایی نظیر نمونهگیری فرعی میتوان مشکل را برطرف کرد.
دادههای کلانبُعدی(High Dimensional Data): یکی از جدیترین محدودیتهای روش استاندارد که بر مبنای محاسبهٔ تابع فاصله کار میکند، ناکارآمدی الگوریتم در مواجه با مجموعهٔ دادههای کلانبُعدی است. در فضاهای کلانبُعدی، فواصل نقاط نسبت به یکدیگر تقریبا یکسان است و همین امر اندازهگیری مبتنی بر فاصله را عملا ناکارآمد میکند. بدیهی است که الگوریتم iForest نیز در مواجه با این شکل از دادهها عملکرد ضعیفی دارد، اما با اضافه کردن یک آزمون و انتخاب ویژگیهای محدود میتوان باعث افزایش دقت و عملکرد الگوریتم شد.
محاسبه نمره ناهنجاری
استراتژی محاسبه نمره ناهنجاری یک نقطه، براساس معادلسازی مشاهدهٔ ساختاری iTrees با ساختار درختی جستوجوی دودویی (Binary Search Trees) است. این سخن بدین معنا است که رسیدن به یک گره خارجی از iTree برابر با یک جستوجوی ناموفق در BST است. بنابراین محاسبهٔ میانگین طول مسیر که همان h(x) است برای رسیدن به یک گره خارجی از فرمول زیر بهدست میآید:
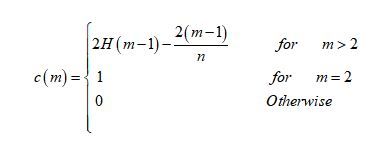
در این رابطه n تعداد دادههای آزمایشی، m حجم نمونه و H عدد هارمونیک است که از رابطهٔ زیر بهدست میآید:
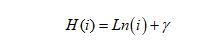
همچنین γ برابر با «ثابت اویلر-ماسکرونی» است که به صورت تقریبی برابر با ۰.۵۷۷ است. همانطور که اشاره شد مقدار c(m) میانگین h(x) است که برحسب m نوشته شده است. بنابراین با انجام یک فرایند نرمالسازی میتوانیم مقدار نمرهٔ ناهنجاری را با توجه به x و m بهدست آوریم که برابر است با:
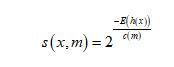
در این رابطه E(h(x)) امید ریاضی است که برابر با مقدار میانگین h(x) بر روی مجموعه درختان iTree است. اکنون با بهدست آوردن این رابطه میتوانیم حالتبندیهای زیر را انجام دهیم:
- اگر مقدار s به ۱ میل کند، آنگاه میتوان گفت که نقطهٔ x یک ناهنجاری است.
- اگر مقدار s به ۰.۵ میل کند، آنگاه میتوان گفت که نقطهٔ x یک نقطه نرمال و متعارف است.
- اگر بهازای همه مقادیر x مقدار s به ۰.۵ میل کند، میتوان گفت که مجموعهٔ داده مذکور فاقد ناهنجاری است و تمام نقاط آن متعارف و نرمال هستند.
رفع مشکل نمره ناهنجاری توسط یک ایرانی
یکی از اصلیترین مشکلات نسخهٔ اولیه الگوریتم iForest محاسبهٔ «نمرهٔ ناهنجاری» بود. این ایراد در سال ۲۰۱۸ توسط سه دانشمند علوم کامپیوتر به نامهای «سهند حریری»، «ماتیاس کاراسکو» و «رابرت برنر» در دانشگاه ایلینوی (University of Illinois) برطرف شد. این افراد مدل جدیدی به نام «جنگل ایزوله توسعه یافته» (Extended Isolation Forest) یا به اختصار EIF را ارائه کردند. این الگوریتم محاسبهٔ نمره ناهنجاری را با دقت بیشتری انجام میدهد.
پیادهسازی جنگل ایزوله در پایتون
در این مرحله یک مثال از پیادهسازی جنگل ایزوله در پایتون را بررسی میکنیم. به منظور سادگی کار یک مجموعه داده دوبعدی را مورد بررسی قرار میدهیم. در گام اول نیاز است که مقداری داده تولید کنیم و تمرکز بیشتری بر روی دادههای نرمال بگذاریم که بهعنوان مجموعهٔ داده آموزشی استفاده میشود. روند آموزش داده و امتیازدهی ناهنجاری استفاده شده را از scikit-learn استخراج کردهایم. در نهایت خواهیم داشت:
# importing libaries ----
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import savefig
from sklearn.ensemble import IsolationForest# Generating data ----
rng = np.random.RandomState(42)
# Generating training data
X_train = 0.2 * rng.randn(1000, 2)
X_train = np.r_[X_train + 3, X_train]
X_train = pd.DataFrame(X_train, columns = ['x1', 'x2'])
# Generating new, 'normal' observation
X_test = 0.2 * rng.randn(200, 2)
X_test = np.r_[X_test + 3, X_test]
X_test = pd.DataFrame(X_test, columns = ['x1', 'x2'])
# Generating outliers
X_outliers = rng.uniform(low=-1, high=5, size=(50, 2))
X_outliers = pd.DataFrame(X_outliers, columns = ['x1', 'x2'مجموعه داده تولیدشده در شکل زیر قابل مشاهده است. همان گونه که در نظر داشتیم، دادههای نرمال که به عنوان مجموعه داده آموزشی مورد استفاده قرار گرفته بودند، در کنار هم هستند. این در حالی است که دادههای پرت به صورت پراکنده هستند.

اکنون باید جنگل ایزوله را آموزش دهیم. در فرایند آموزش دادن، متغیر «آلودگی» را برابر با ۰.۱ قرار دهیم که همان مقدار پیشفرض scikit-learn است.
# Isolation Forest ----
# training the model
clf = IsolationForest(max_samples=100, random_state=rng)
clf.fit(X_train)
# predictions
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)اکنون که الگوریتم کار پیشبینی و شناسایی دادههای ناهنجار را ادامه داده است. دنبال آن هستیم که عملکرد iForest را در شناسایی دادههای پرت بررسی کنیم. بنابراین به شکل زیر عمل میکنیم:
# new, 'normal' observations ----
print("Accuracy:", list(y_pred_test).count(1)/y_pred_test.shape[0])
# Accuracy: 0.93# outliers ----
print("Accuracy:", list(y_pred_outliers).count(-1)/y_pred_outliers.shape[0])
# Accuracy: 0.96در نگاه اول اینطور به نظر میرسد که عملکرد الگوریتم بسیار خوب و شناسایی نقاط ناهنجار با دقت بالایی انجام شده است. تنها نکتهای که وجود دارد این است که تعدادی از دادههای پرت که به صورت تصادفی ایجاد شدهاند در ناحیهٔ هنجار و نرمال قرار گرفتهاند، اما همچنان به عنوان ناهنجاری و داده پرت شناسایی شدهاند. برای افزایش دقت و کاهش خطاهای اینچنینی میتوانیم تغییراتی در متغیرهایی نظیر؛ آلودگی، تعداد تخمینگرها و ... ایجاد کنیم و بار دیگر خروجی را بررسی کنیم. با این حال نتایج خروجی بهدست آمده کاملا رضایتبخش است.
استفاده از کاربرد جنگل ایزوله در سُکان
جمعآوری دادههای فروش مشتریان و ارائهٔ تحلیل و گزارشهای متنوع مبتنی بر این دادهها یکی از مهمترین فرایندهایی است که در محصول سکان رخ میدهد. بدیهی است که برای انجام تحلیل دقیقتر نیاز است تا دادههای ناهنجار و نامتعارف شناسایی و از مجموعهٔ دادهٔ نهایی حذف شوند تا دقت خروجی افزایش داشته باشد. به همین دلیل تیم فنی سکان اقدام به طراحی و توسعهٔ یک ماژول شناسایی ناهنجاری کرده است. یکی از الگوریتمهای به کار رفته در توسعه این ماژول iForest است که با دقت و عملکرد قابلقبولی به شناسایی ناهنجاریها و دادههای نامتعارف میپردازد. از این ماژول شناسایی ناهنجاری در بخشهای مختلفی از محصول سکان نظیر انجام تحلیل RFM و پیشبینی ریزش استفاده میشود.
مطلبی دیگر از این انتشارات
راهاندازی سرور CI: کوزهگری که از کوزهشکسته آب میخورد!
مطلبی دیگر از این انتشارات
ایدهای جسورانه برای بالا نگهداشتن سرویس - قسمت دوم
مطلبی دیگر از این انتشارات
استقرار تحلیل پیشبینی ریزش مشتریان در محصول