

مهندس نرم افزار | متخصص علوم داده
استقرار تحلیل پیشبینی ریزش مشتریان در محصول

قبلا در این مطلب به توضیح درباره تحلیل پیشبینی ریزش مشتریان و نکات فنی مربوط به این تحلیل پرداخته بودیم. در این قسمت میخوایم سراغ استقرار تحلیل پیشبینی ریزش در محصول بریم. تجربهای که در سحاب و روی محصول سکان بهدست آوردیم و دوست داشتیم اون رو به اشتراک بذاریم.
همون طور که میدونید بین استفاده از یادگیری ماشین و یادگیری عمیق در آزمایشگاه و در صنعت اختلاف معناداری وجود داره. وقتی در محیط Colab اقدام به توسعه مدل میکنید، صرفا بر روی دادگان مشخصی آزمایش انجام میدهید که اتفاقا سعی بر اینه که مدل ایجاد شده تعمیمپذیری خوبی داشته باشه اما این به این معنا نیست که وقتی در پروداکشن قرار میگیره میتونه به خوبی عمل کنه. وقتی یک مدل مبتنی بر یادگیری ماشین وارد یک محصول میشه باید بتونه به خوبی نیازهای فنی و بیزینسی رو پوشش بده. در واقع تحلیل ما به عنوان مثال بخشی از یک سمفونیه که باید درست نواخته بشه. مثلا اگه محصول ما با سریهای زمانی سروکار داشته باشه، مدل آموزش داده شده بعد از مدتی منقضی میشه و اگه مانیتورینگ خوبی برای عملکردش داشته باشید متوجه میشید که کیفیت عملکردش افت پیدا کرده. تا همین جا دو نیازمندی مهم برای استقرار مدل پیشبینی ریزش مشتریان در محصول مشخص شد. اول اینکه باید بتونیم به صورت دورهای با دادههای تازه و تمیز اونها رو re-train کنیم و همچنین بتونیم عملکردشون رو هم مانیتور کنیم.
همچنین همون طور که در این مطلب توضیح دادیم، انجام تحلیل پیشبینی ریزش مشتریان، نیازمند استخراج ویژگیهای متعدد از دیتای تراکنشهای بیزینس هست که فرایندی زمانبره. در فاز اکسپریمنت (experiment) میتونیم براش صبر کنیم اما در فاز پروداکشن و بهخصوص زمان inference نیاز داریم که خیلی سریع انجام بشه. این قسمت بیشتر یک فرآیند مهندسی دادهست و از سرویس ETL سکان به عنوان ورودی، این فیچرها رو طلب میکنیم و اینکه چهطوری در لحظه، فیچرهای مورد نیازمون آماده میشن رو به یک پست دیگه واگذار میکنیم.
نکتهی مهم دیگه اینه که وقتی بر روی یک محصول و داخل یک تیم کار میکنیم نیاز داریم تا از نتایج کارهای همدیگه آگاه باشیم و هر موقع که لازم شد بتونیم به اکسپریمنتهای گذشته رجوع کنیم. طبیعتا این حالت هم با حالتی که تنهایی نشستیم و داریم توی Colab خوشگذرونی میکنیم فرق میکنه. در این حالت لازمه که بدونیم هر اکسپریمنت دقیقا با چه دیتایی اجرا شده و چه مدلی رو خروجی داده. به عبارت دیگه نیاز داریم تا experiment tracking انجام بدیم.
طرف دیگه ماجرا هم یکسری نیازمندیهای بیزینسی هست. همون طور که قبلا توضیح دادیم، پیشبینی ریزش مشتریان در واقع نوعی تلاش برای شناسایی آن دسته از مشتریانی ست که قبلا خیلیخوب از ما خرید میکردند ولی به مرور زمان خریدهای کمتری انجام میدن. هر چقدر زودتر بتونیم تشخیص بدیم که یک مشتری میخواد از پیش ما بره بهتره. اینجاست که به یک مدل پیشبینیکننده با دقت و حساسیت بالا نیاز داریم. در واقع مدل آموزش داده شده قراره کار forecast انجام بده. خروجی این مدل به صورت یک عدد احتمالاتی بین ۰ و ۱ است. به این معنی که هر چقدر عدد خروجی به عدد یک نزدیک باشه یعنی احتمال رویگردانی اون مشتری بیشتر میشه و هر چقدر به صفر نزدیکتر باشه احتمالا اون مشتری باز هم از بیزینس ما خرید خواهد کرد. تا اینجا همهچیز به نظر شیک و مجلسی میاد اما بر اساس اکشنی که بیزینس مورد نظر میخواد با مشتریان در معرض ریزش انجام بده خروجی میتونه متفاوت بشه. اون چیزی که برای بیزینس مهمه یک عدد احتمالاتی نیست بلکه مدل ما باید بگه چه کسانی ریزش میکنند و چه کسانی فعال خواهند ماند. پس در واقع باید خروجی صفر و یک به محصول برگردونیم و از همین جا پای یک threshold به میون میاد. نقش این threshold در اینه که مشتریانی با احتمال بیش از threshold رو به عنوان ریزشکرده در نظر بگیریم. اما هر چقدر این threshold رو سختگیرانهتر در نظر بگیریم میزان precision رشد میکنه اما میزان recall با کاهش مواجه میشه. از همینجا باید بتونید در محصول یک تعادلی بین این دو معیار برقرار کنید. همچنین چون طبق توضیحات قبلی، پیشبینی ریزش مشتریان اساسا یک مسئله با دادگان imbalanced هست پس لایه آخر مدل آموزش داده شده (که عموما از جنس sigmoid) است به سمت عدد صفر بایاس میشه. به این صورت که اگه نمودار ROC و یا PR اون رو بکشید به ازای thresholdهای بسیار نزدیک به صفر، تعادل مناسبی بین precision و recall برقرار میشه. برقراری تعادل بین precision و recall و همچنین حد آستانه درنظرگرفتهشده یکی دیگه از نکات مهمیه که باید در استقرار مدل در محصول مدنظر قرار داده بشه.

و اما نکته اصلی! بله؛ اصلا لازم داریم تا مدل آموزش داده شده به دیگر بخشهای سیستم سرویسدهی کنه و عملیات inference رو پشتیبانی کنه. پس یکی دیگه از نکات مهم استقرار تحلیل پیشبینی ریزش در محصول، نحوه سرویسدهی مدل به دیگر ماژولهای سرویس سکان است. در ادامه به سیر تکاملی راهحلهایی که در سکان به اونها رسیدیم میپردازیم و سعی میکنیم مزایا و معایب هر کدوم از این practiceها رو بیان کنیم.
راهحل اول؛ خیلی ساده، خیلی عالی! Python SDK
در این راهحل کل لاجیک مدلسازی و inference رو در یک پکیج پایتون پیادهسازی کردیم. سپس باید این پکیج در کدبیس back-end ایمپورت بشه تا این تیم بتونه ازش استفاده کنه. از خوبیهای این راهحل اینه که تا حدی به separation of concerns نزدیک شده اما از نکات منفیش اینه که هنوز وابستگیهای نامناسبی وجود داره. مثلا از تنسورفلو در SDK ما استفاده شده و وقتی back-end هم میخواد ازش استفاده کنه باید تنسورفلو رو نصب کنه که نگهداری و نصبش در back-end هم خودش داستانهایی داره. از طرفی هنوز یکی از خواستههای ما یعنی re-train های منظم در بازههای زمانی مختلف رو پشتیبانی نمیکنه و این کار رو باید تیم back-end خودش انجام بده که این یعنی یک لاجیک از تیم دیتا به تیم back-end منتقل شده و این هم نکته خوبی نیست. همچنین مانیتورینگ عملکرد مدلها نیز باز به عهده تیم back-end هست که با توجه به اینکه این مدلها مبتنی بر یادگیری ماشین هستند مانتورینگشون هم میتونه پیچیدگیهای خاص خودش رو داشته باشه. از همه مهمتر این پکیج پایتونی مثل همه کدبیسهای دیگه نیازمند استقرار فرآیندهای دقیق و تمیز مهندسی نرمافزار است. مشکل اینجاست که لاجیک این تحلیل در تیم دیتاساینس وجود داره در حالیکه پیادهسازی اون رو احتمالا باید افراد دیگهای انجام بدن. علتش هم اینه که عموما دیتاساینتیستها اصول پیادهسازی تمیز کد رو بهخوبی توسعهدهندههای دیگه انجام نمیدن. همین گلوگاه مهم میتونه مشکلآفرین باشه چون نیازمند تعامل بسیار نزدیک تیم دیتا و تیم بکاند هست.
اما نیازمندی بیزینسی که در بالا مطرح کردیم یعنی همون استفاده از حد آستانه مشخص، در این SDK پیادهسازی شده و به back-end این اجازه رو میده که هم برچسب ۰ و ۱ و هم احتمالات رو از این پکیج دریافت کنه. نکته مهم اینه که سرویس سکان باید پیشبینی ریزش مشتریان رو برای بیزینسهای متفاوتی پشتیبانی کنه و به عبارتی قراره این تحلیل و تحلیلهای دیگه رو به مثابه یک سرویس برای بیزینسها فراهم کنه. قطعا توزیع دیتای هر بیزنس از دیگری متفاوته. از همین جا سختی کار با یک ترشولد ثابت مشخص میشه. در حالتی که این تحلیل فقط برای یک دیتاست و برای یک بیزینس طراحی شده باشه، چنانچه ترشولد تصمیمگیری نهایی بر روی مقادیر نزدیک به صفر بایاس شده باشه مشکلی پیش نمیاد. چرا که با رسم نمودار ROC و یا PR میتونیم ترشولد مناسب رو جهت برقراری تعادل پیدا کنیم. اما اینجا لازم داریم که همواره بهترین تعادل بین precision و recall بر روی مقدار ۰.۵ در تابع sigmoid قرار بگیره چرا که سختی تحلیل رو کاربر بر اساس نیاز بیزینس باید بتونه تنظیم کنه و لازم هست که در همه بیزینسها این اسلایدر تعریف و مفهوم یکسانی داشته باشه. چیزی که در وهله اول به نظر میرسه اینه که با down-sampling بشه بایاس شدن لایه sigmoid رو حل کرد. بنابراین لاجیک down-sampling رو هم در این پکیج پیادهسازی کردیم تا از بایاس شدن تابع sigmoid به دلیل وجود دادههای imbalanced جلوگیری بشه.
همچنین عملا اکسپریمنتهایی که تیم دیتا انجام داده هم خیلی به ورژن کد مپ نشده و عملا این دو تا فاز از هم کاملا جدا هستند. به عبارتی کار اکسپریمنت در یک ریپو و کار استقرار تحلیل در محصول هم در یک ریپوی دیگه انجام میشه. این جدایی میتونه کار ما رو برای بهبودهای آینده تحلیلها سخت کنه. همچنان اکسپریمنتها در کولب انجام میشه و کسی از حال دیگری خبری نداره! که این هم نشونه خوبی نیست.
راهحل دوم؛ Kubeflow و دیگر هیچ!
خب همون طور که دیدید راهحل قبلی نقایص بسیاری داره که باید سعی کنیم اونها رو برطرف کنیم. یک راهحل مناسب که نسبتا بهروز و جدید هست استفاده از kubeflow هست که مبتنیه بر kubernetes. استفاده از کیوبفلو مزیتهای زیر رو داره:
- با استفاده از kubeflow میتونیم تحلیل پیشبینی ریزش رو به صورت یک پایپلاین خوشتعریف دربیاریم.
- میشه اکسپریمنتهای مختلفی رو برای این پایپلاین تعریف کنیم که در نتیجه کل تیم میتونه به همه این اکسپریمنتها دسترسی داشته باشه.
- میتونیم برای هر پایپلاین زمانبندی training تعریف کنیم که به صورت دورهای کار آموزش بر روی دادگان جدید انجام بشه.
- هر دادگانی که برای اکسپریمنت استفاده میشه بر روی یک minio server که در کنار kubeflow بالا اومده ذخیره میشه. این دیتاستها تحت عنوان آرتیفکت اولین کامپوننت پایپلاین ذخیره میشن که کارش آمادهسازی دادگان برای تحلیله. میشه برای کامپوننتهای مختلف، آرتیفکتهای متفاوتی تعریف کرد و اونها رو ذخیره کرد.
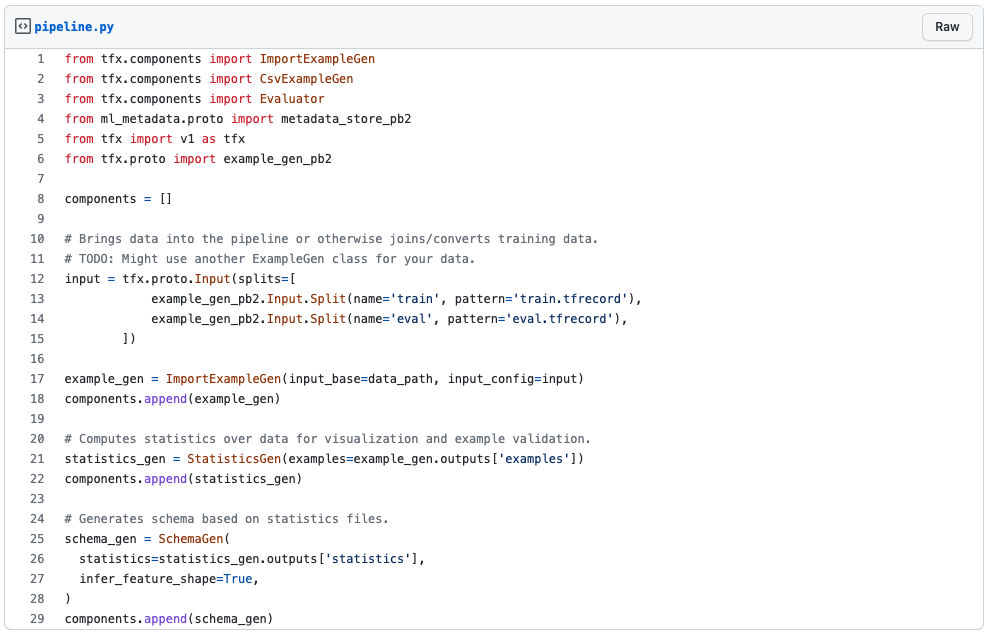
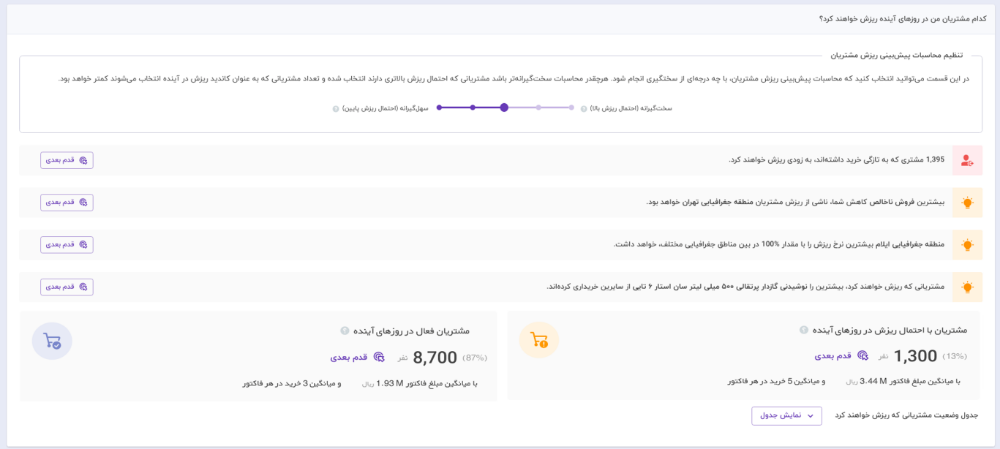
برای استفاده از kubeflow لازمه که پایپلاینهامون رو بتونیم به فرمتی که این ابزار میفهمه بنویسیم. چیزی که این ابزار میفهمه یک فایل yml پیچیده است که تقریبا هیچ بنیبشری به این راحتیا نمیتونه ازش سر دربیاره اما خوشبختانه کیوبفلو یک DSL به زبون پایتون داره که با استفاده از اون میتونید پایپلاینتون رو توصیف کنید. اما کار به همینجا ختم نمیشه. از اونجایی که برای مدلسازی از ابزار tensorflow استفاده کردیم به راحتی میتونیم از مابقی استک tensorflow هم لذت ببریم. در همین راستا میشه از ابزار TFX استفاده کرد. در واقع به جای اینکه سراغ استفاده از DSL کیوبفلو بریم میتونیم از TFX استفاده کنیم. خب شاید بپرسید که چه مزیتی داره؟ اولین نکتهش اینه که در واقع TFX یک لایه بر روی کیوبفلو هست. یعنی شما اگه پایپلاینتون رو با TFX توصیف کنید میتونید هم بر روی kubeflow اجراش کنید و هم بر روی orchestrator های دیگه مانند apache airflow. نحوه توصیف چند کامپوننت از پایپلاین تحلیل پیشبینی ریزش مشتریان رو در بالا میتونید ببینید. پس در واقع یک لایه با یک زبان مشترک به نام TFX ایجاد شده که پایپلاینهایی که با اون توصیف کردید رو میتونید بر روی زیرساختهای مختلف اجرا کنید. از طرفی چون تمرکز TFX بر روی ایجاد پایپلاین برای train مدلها و استقرار در محصول بوده تعداد مناسبی از کامپوننتهای ازپیشتعریفشده داره که مثل هلو میتونید ازش استفاده کنید. کل پایپلاین تحلیل پیشبینی ریزش مشتریان در تصویر زیر قابل مشاهده است.
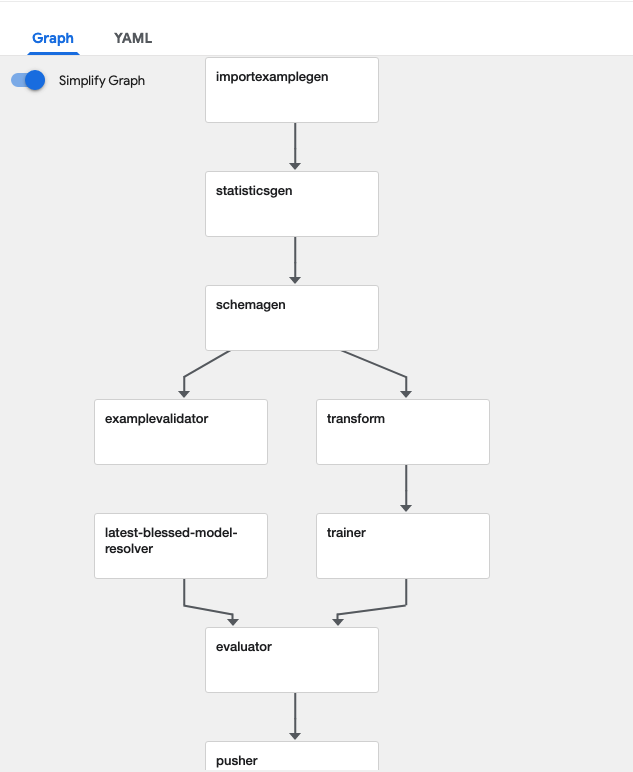
در این تحلیل ابتدا باید دیتاست موردنظر به پایپلاین وارد بشه که این کار رو کامپوننت importexmaplegen انجام میده. سپس یک سری آماره بر روی دیتای ورودی حساب میشه تا با استفاده از اون آمارهها بشه دادههای پرت رو شناسایی کرد. همچنین دادههایی که با schemaی موردنظر تطابق ندارند نیز باید کنار گذاشته بشن که این کارها به ترتیب به عهده statisticsgen و schemagen هست. بعد از اون نوبت برخی از pre-processها میرسه که با استفاده از کامپوننت transform انجام میشه. (برای اینکه جزئیات پیادهسازی این تحلیل و لاجیکهای هر یک از این کامپوننتها رو متوجه بشید میتونید به این پست مراجعه کنید). حالا دیگه دیتا آماده شده و میتونیم با استفاده از کامپوننت trainer اقدام به آموزش مدل کنیم. در واقع بیشترین لاجیک مربوط به تحلیل، در کامپوننتهای transform و trainer پیادهسازی میشه. به دلیل اینکه از TFX استفاده میکنیم، خیلی راحت میتونید برای توصیف معماری مدل از Keras استفاده کنید. بعد از آموزش هم، مدل آموزش داده شده با بهترین مدل موجود که تا الان توی scope تیم شما طراحی شده مقایسه میشه و چنانچه مدل جدید آموزش داده شده با معیارهای مورد نیازی که تعریف کردیم تطابق داشته باشه، کامپوننت evaluator اون رو برای کامپوننت بعدی میفرسته و همچنین اون رو به عنوان بهترین مدل جایگزین مدل قبلی میکنه. در این مرحله اگه به موفقیتی نرسیده باشیم پایپلاین همین جا به اتمام میرسه و دیگه جلوتر نمیره. چنانچه مدل بهتری رو تونسته باشیم تولید کنیم، کار دست کامپوننت pusher میافته و کارش اینه که مدل رو ذخیرهسازی کنه و مدل رو به فرمت SavedModel در tensorflow ذخیره میکنه.
اما همچنان یک چالش اصلی باقی مونده. اینکه مدلهایی که به عنوان خروجی پایپلاین این تحلیل تولید میشن باید serve بشن. اینطوری میتونیم با معماری میکروسرویس به دیگر تیمهای فنی سرویسدهی بکنیم که خب معماری جا افتاده و درستودرمونی هست. برای serve کردن مدل هم از tensorflow serving استفاده میکنیم. این ابزار میتونه خروجی پایپلاین رو سرو کنه به این صورت که برای هر مدل یک endpoint API ایجاد میکنه. در واقع خروجی پایپلاینی که در بالا توضیح دادیم به عنوان ورودی برای tensorflow serving استفاده میشه. ابزار tensorflow serving به طور دائم به محل ذخیرهسازی کامپوننت pusher نگاه میکنه و چنانچه مدل جدیدی توسط کامپوننت pusher ایجاد شده باشه مدل قبلی رو به نرمی پایین میاره و مدل جدید رو serve میکنه (تاکید روی به نرمی داریم به خاطر اینکه فقط تقریبا اندک لحظهای حس پایین بودن سرویس ایجاد میشه و همهچیز خیلی smooth هندل شده است). البته این وسط برای tensorflow serving میتونید version policy های زیادی رو ست کنید.
جمعبندی
بدین ترتیب تونستیم یک تحلیل پیشبینیمحور رو که صرفا باهاش اکسپریمنت کرده بودیم، در پروداکشن ایجاد کنیم. با استفاده از مکانیزمهای بالا عملیات re-training با استفاده از زمانبند کیوبفلو انجام میشه و همچنین عملیات inference هم با استفاده از endpoint APIهایی که tensorflow serving برامون فراهم کرده صورت میپذیره. با استفاده از kubeflow میتونیم اکسپریمنتهامون رو track کنیم و آرتیفکتهای هر بار اجرای پایپلاین رو هم بر روی minio-server به صورت ذخیرهشده داشته باشیم.
پروژهای که در بالا توضیح دادیم تنها یکی از فعالیتهای تیم دیتا در شرکت سحاب بود. امیدواریم که از تجربهای که ما داشتیم بهترین استفاده رو ببرید!
مطلبی دیگر از این انتشارات
کسب و کارها چطور با استفاده از هوش مصنوعی اثرات اجتماعی ایجاد میکنند؟ (بررسی گزارش دیجیکالا)
مطلبی دیگر از این انتشارات
ساخت API مدرن با GraphQL، بخش اول
مطلبی دیگر از این انتشارات
برای ارتقای کیفیت توسعهی نرمافزار از کجا شروع کنیم؟