

مهندس نرم افزار | متخصص علوم داده
داستان یک سقوط: پیشبینی ریزش مشتریان!

همیشه مشتری به عنوان یه موجودیت ارزشمند برای کسبوکارهای مختلف حساب میشده. کسی یا سازمانی که با هزینه به عنوان مشتری بهدست میومده و قرار بوده برای کسبوکار منبعی از درآمد باشه. حالا قطعا ازدست دادن یه همچین موجودی! میتونه خیلی برای هر کسبوکاری دردناک باشه به خاطر همین اگه بتونیم زودتر جلوی این داستان ناگوار رو بگیریم قطعا به کسبوکار کمک کردیم. از اینجاست که پیشبینی این سقوط، مهم و تاثیرگذار میشه.
توی این پست قصد داریم که یه تحلیل تمیز از ریزش مشتریان ارایه بدیم و تجربهای که خودمون توی سکان بهدست آوردیم رو با یه دیتای عمومی که اتفاقا توی آوردگاه کگل هم میشه پیداش کرد، توضیح بدیم. این دادگان شامل اطلاعات کمپینها و تخفیفها و تراکنشها ست. اما ما فقط از اطلاعات تراکنشها استفاده میکنیم چرا که خیلی مواقع فقط اطلاعات تراکنشها در دسترس هستند گرچه نوتبوکهای دیگهای که روی این دادگان منتشر شدن از اطلاعات دیگهای هم استفاده کردن. کد کامل این تحلیل رو میتونید اینجا ببینید.
خواندن دادگان و بررسیهای اولیه

در این دادگان چند ویژگی نقش کلیدی بازی میکنن. ویژگی household_key در واقع شناسه مشتریان کسبوکاره. همچنین ویژگی BASKET_ID شناسه سفارش مشتریانه. هر سفارش میتونه شامل چندین کالا باشه که در این صورت ممکنه یک شناسه سفارش در چندین سطر تکرار بشه تا کالاهای مختلف یک سفارش اعلام بشن. ویژگیهای QUANTITY و SALES_VALUE نیز به ترتیب، تعداد کالا در آن سطر سفارش و حجم خرید از آن کالا در سطر سفارش رو مشخص میکنه.
قبل از مدلسازی لازمه تا بررسیهای آماری روی دادگان انجام بدیم. برای این کار خوبه که روی ویژگیهای کلیدی، مقادیر بیشینه و کمینه و توزیع متغیرها رو بدونیم. همین طور بفهمیم که کجاها مقادیر غیر معقول وجود داره یا مثلا چه سطرهایی مقادیر None دارن. یکی از مقادیر مرسوم در دیتای فروش کسبوکارها، مقادیر منفی برای QUANTITY یا SALES_VALUE هست که نشوندهنده سفارشهای برگشتی هست. برخی جاها هم ممکنه برای این نوع سفارشها مقادیر صفر رو در نظر بگیرن. تو این دادگان همین اتفاق افتاده. برای تحلیل لازمه که این سفارشها حذف بشن تا توی سفارشهای هر مشتری لحاظ نشن. ( البته ممکنه شما ایده بزنین و از دل همین سفارشها هم بخواین ویژگی در بیارین ولی چیزی که مهمه اینه که نباید با این سفارشها مثل سفارشهای عادی برخورد بشه و ما هم سادهترین راه رو انتخاب کردیم ینی حذف ! )

همچنین مقادیر None رو هم بر روی دادگان بررسی میکنیم که اگه وجود داشتن یه فکری به حالشون بکنیم. برای ویژگیهای کلیدی household_key و BASKET_ID و SALES_VALUE هیچ مقدار None ای وجود نداره.
بررسی مشتریان
در این مرحله میخوایم از داده تراکنشها به داده مشتریان برسیم. برای همین بر اساس household_key باید group_by کنیم و ویژگیهای مختلفی از جمله تعداد خرید هر مشتری یا frequency و مجموع خرید هر مشتری یا monetary رو استخراج کنیم. تابع convert_transaction_to_customers ویژگیهای مختلف رو از تراکنشها استخراج میکنه. لازمه به این نکته توجه کنیم که برخی مشتریان به صورت خیلی کم از کسبوکار خرید انجام دادهاند و به نوعی مشتریان غیرعادی تلقی میشوند. به همین دلیل توزیع frequency رو بر روی مشتریان بررسی میکنیم تا یه سطح آستانه مشخص برای مشتریان پیدا کنیم و مشتریانی که کمتر از اون مقدار دفعات خرید داشتن رو حذف کنیم.

فضای ویژگی جدیدی که برای مشتریان بدست اومده از روی اطلاعاتی هست که از متخصصان این دامنه گرفته شده. این ویژگیها میتونن تفسیر نسبتا خوبی از رفتار خرید هر مشتری ارایه بدن. مثلا مقدار recency فاصله زمانی آخرین خرید هر مشتری از تاریخ روز هست. یا مثلا product_diversity برابر تعداد انواع کالایی هست که هر مشتری خریده. پارامتر periodicity هم فاصله زمانی بین هر خرید مشتری هست که آمارههای مختلف مانند میانگین و انحراف از معیار و ... بر روی اون حساب شده. مقدار AOV هم برابر میانگین ارزش خرید هر مشتری هست. توزیع ویژگیهای بالا رو میتونین ببینین.

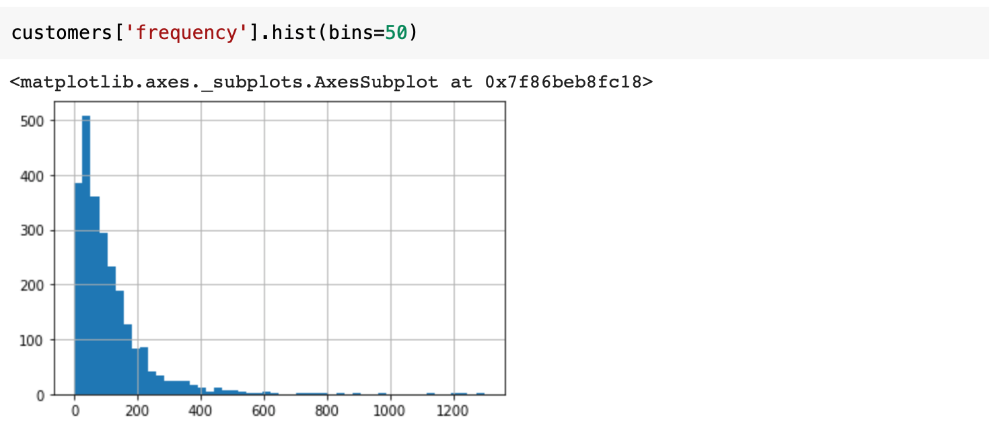
با بررسی توزیع frequency، مشتریانی که کمتر از ۱۰ بار خرید انجام دادن رو حذف میکنیم. این مشتریان به نوعی داده پرت محسوب میشن و میتونن تعمیمپذیری مدل احتمالاتی رو خراب کنن.
یه پارامتری که خیلی میتونه توی تحلیل ریزش موثر باشه مقدار D/F یه کسبوکار هست. مقدار D/F همان میزان duration هر مشتری تقسیم بر مقدار frequency همون مشتریه و میانگین مقادیر D/F یه پارامتر مهم هست که رفتار کلی کسبوکار رو براساس دفعات خرید تعیین میکنه. پارامتر duration هم به میزان حضور یه مشتری توی کسبوکار برمیگرده ینی بازه بین اولین و آخرین خرید هر مشتری. با پارامتر D/F جلوتر کار داریم! اما علی الحساب بدونین که این مقدار برای این دادگان حدود ۱۱.۱۹ روز هست. به این معنی که توی این کسبوکار امید میره که هر مشتری حدودا هر ۱۱ روز یکبار خرید انجام بده. البته توی محاسبه این KPI هم لازمه که اول مشتریان تک خرید حذف بشن چرا که مقدار duration برای این مشتریان برابر صفر هست و این مقدار میتونه ما رو گمراه کنه.
تعریف ریزش مشتریان
قبل از ورود رسمی به مساله باید که ریزش یک مشتری رو تعریف کنیم. برای ریزش مشتریان تعریف رسمی وجود نداره ولی با توجه به اطلاعاتی که از متخصصان این دامنه گرفتیم معمولا مشتری که بیش از مقدار دو برابر میانگین D/F توی کسبوکار خریدی انجام نده به عنوان یه مشتری ریزش کرده شناسایی میشه. اینجاست که اهمیت این پارامتر مشخص میشه. البته ما روی دادگان های مختلف با D/F های متفاوت هم تست کردیم و دیدیم که یک مدل بر روی کسبوکارهایی با D/F های نزدیک بهم تا حد بسیار زیادی نتایج یکسان ارایه میکنه و این نشون میده که توی تحلیل ریزش مشتریان این پارامتر میتونه نقش کلیدی ایفا کنه.
با توجه به تعریف بالا لازمه که از روی دیتای تراکنشهای کسبوکار، الگوهای رفتاری خرید مشتریان رو بهدست بیاریم و بعد اینها رو براساس تعریف ریزش مشتری، برچسب بزنیم تا برای فاز مدلسازی آماده بشیم. برای این کار یک پنجره لغزان M روزه رو با گام S روزه بر روی داده تراکنشها حرکت میدیم. باید تابعی داشته باشیم تا رفتار M روزه هر مشتری رو به یه فضای ویژگی جدید ببره که بتونه رفتار اون مشتری رو توصیف کنه و بعد هم چنانچه توی N روز آینده خریدی انجام نداده بود، به اون الگوی رفتاری برچسب ۱ ( بهمعنای ریزش کرده) و در غیر این صورت برچسب ۰ بزنه. این تبدیل رو تابع transform_data انجام میده. شیوه کار به این صورته که رفتار خرید M روزه مشتری شامل یه سری ویژگیهای تجمیعی از قبیل تعداد دفعات خرید در اون بازه، حجم خرید در اون بازه و یا فاصله آخرین خرید مشتری تا آخرین روز بازه خواهد بود.( تعداد این ویژگیهای تجمیعی ۱۲ تاست ). همچنین به ازای هر روز در این بازه، چنانچه مشتری در اون روز خریدی انجام داده باشه حجم خرید در اون روز و تعداد انواع کالا و تعداد کالایی که خریده رو در ۳ بعد اضافه میکنه و در غیر این صورت مقدار هر یک از این سه بعد رو برابر با صفر میذاره. با توجه به این توضیحات رفتار M روزه مشتری با یه بردار 12+3*M بعدی توصیف میشه و اگر هم در بازه N روزه آتی خریدی نداشت مقدار label برای اون الگوی رفتاری مشتری برابر ۱ و در غیر این صورت برابر صفر خواهد بود.
مقدار N با توجه به تعاریف بالا برابر با حدود دو برابر شاخص D/F ینی ۲۰ روز خواهد بود و مقدار M هم باید با Hyper-Parameter-Setting به دست بیاد که با آزمایشاتی که ما انجام دادیم این مقدار برابر با ۴۰ روز هست. همچنین پارامتر S هم با توجه به نرخ انجام تراکنش توی اون کسبوکار انجام میشه. در این دادگان هر ۱.۱ روز یه تراکنش انجام شده به همین دلیل مقدار S رو برابر با ۲ روز گذاشتیم. با استفاده از تحلیل PCA میتونیم این فضای ۱۳۲ بعدی را در سه بعد ببینیم.


با توجه به توضیحات بالا مساله ریزش برای این دادگان به این صورت تعریف میشه که رفتار ۴۰ روزه هر مشتری رو به عنوان ورودی میگیریم و پیشبینی میکنیم که آیا در ۲۰ روز آینده خریدی انجام خواهد داد یا خیر. قبل از هر چیز باید دیتای آموزش رو از دیتای تست جدا کنیم. برای اینکه مدل ما تعمیمپذیری بیشتری داشته باشه باید این دیتاها رو با توجه به فاز زمانی از هم جدا کنیم. مثلا دیتای تراکنش a روز اول رو برای آموزش و b روز بعدی رو برای تست در نظر بگیریم. به دلیل اینکه پارامتر های مساله رو تعیین کردیم پس دیتای ۶۰ روز آخر رو برای تست و مابقی دیتا رو برای آموزش درنظر میگیریم.


مدل سازی
با توجه به اینکه نسبت دادههای ریزش کرده به ریزش نکرده حدود ۱ به ۶ هست، داده موجود از نوع imbalanced هست. فرآیند یادگیری در این مدلها میتونه تا حد زیادی سخت و دشوار باشه. این هم به این دلیله که شبکه عصبی ممکنه به سمت کلاسی که داده بیشتری ازش موجود هست غش کنه!! و همزمان اگه از کلاس کمیابتر دیتای کافی وجود نداشته باشه حتی توزیع داده کمیابتر رو هم نمیتونه یاد بگیره. متدهای زیادی وجود داره که توی مساله دستهبندی با داده های imbalanced بتونیم ازشون استفاده کنیم و مدل رو بهتر آموزش بدیم. با توجه به اینکه از کلاس کمیاب، ینی الگوهای رفتاری ریزش کرده، نسبتا تعداد دادههای مناسبی وجود داره ( حدود ۱۰۰ هزار الگوی ریزش داریم) میتونیم از تکنیک under-sampling استفاده کنیم به این صورت که از دستهای که دیتای بیشتری از اون موجوده به صورت تصادفی حدود ۱۰۰ هزار دیتا برمیداریم تا تعداد دو کلاس با هم بالانس بشه. اما چون دوست داریم از دیتاهای خوبی که از کلاس الگویهای ریزش نکرده داریم هم به خوبی استفاده کنیم ابتدا مدل رو روی کل دادهها آموزش میدیم و بعد با Fine-Tuning به صورت بالانس شده شبکه رو آموزش میدیم. مد fine-tuning ای که استفاده میکنیم هم به صورت ساده و INIT هست ینی با همان وزنهایی که شبکه در مد اول آموزش دیده، آموزش رو ادامه میدیم. معماری شبکه و تعداد پارامترهای آن در زیر اومده.

در این شبکه از لایههای batch_normalization استفاده شده تا استانداردسازی دادهها در سطح معماری شبکه انجام بشه. همچنین برای جلوگیری از آورفیت شدن شبکه از dropout با نرخ ۰.۵ استفاده کردیم. از طرفی از تکنیک early_stopping نیز استفاده کردیم تا هر چه بیشتر از دادههای آموزشی استفاده کنیم و از آورفیتینگ دورتر بشیم. این شبکه را یکبار با کل دادهها و بعد هم با دادههای بالانس شده آموزش دادیم. نمودار دادههای بالانس شده به صورت زیر هست.


آموزش شبکه و ایجاد شبکه عصبی توسط ابزار Keras انجام شده که API بسیار سادهای برای طراحی و آموزش شبکههای عصبی عمیق داره. همچنین معیار ارزیابی رو معیار AUC یا Area Under Curve انتخاب کردیم. علت هم اینه که هم مساله با دیتای Imbalanced رو به رو هست و هم اینکه لایه آخری که برای تصمیمگیری کلاس داده استفاده شده تابع Sigmoid هست که یه عدد احتمالاتی بین ۰ تا ۱ برمیگردونه و خیلی مهمه که حد آستانه رو برای این تابع چه عددی در نظر بگیریم تا مشخص بشه از چه احتمالی بیشتر رو باید به عنوان یک الگوی ریزش در نظر گرفت. با نمودار ROC میتونیم این مقدار رو به راحتی تنظیم کنیم البته باید توجه کنیم که در این حالت باید حتما دیتای validation جداگانه ای هم داشته باشیم تا ازش برای تنظیم این پارامتر استفاده بشه. تابع loss هم با توجه به ذات مساله تابع BinaryCrossEntropy انتخاب شده. در ادامه نحوه تغییر معیار ارزیابی و تابع loss در طول فرآیند آموزش قابل مشاهده ست.


تحلیل خطا
با اقدامات انجام شده نتایج به دست اومده رو میتونیم روی ماتریس زیر ببینیم:

با توجه به ماتریس بالا میزان recall حدود ۷۰ درصده. ینی از بین تمام الگوهای ریزش تونستیم ۷۰ درصدشون رو تشخیص بدیم. از طرفی مقدار precision نیز ۴۰ درصد هست. ینی از بین الگوهایی که بهعنوان ریزش پیشبینی کردیم حدود ۴۰ درصدشون واقعا ریزش کرده بودن. اما علت اینکه مقدار precision پایین هست چیه و آیا بهتر میتونه بشه یا نه؟ این سوال مهمی هست که با تحلیل خطاهای موجود میتونیم بفهمیم وضعیت چه طوره!

با بررسی خطاهای false positive ینی مشتریانی که ریزشی نبودن ولی ما اونا رو ریزشی پیشبینی کردیم متوجه میشیم که اغلب اونا ( ینی حدود ۷۰ درصد) کسانی هستن که فقط ۱ خرید داشتن. پس ینی خیلی به ریزش نزدیک بودن در حالی که مشتریانی که ریزشی نبودن و ما هم اونا رو درست تشخیص دادیم عموما ۲ یا ۳ یا ۴ خرید داشتن. همچنین میتونیم ۴ دسته ماتریس درهمریختگی رو از منظر آمارههای D/F و یا recency بررسی کنیم که ببینیم ایا بر روی این ویژگیها هم میتونیم جداسازی داشته باشیم یا نه.


از روی نمودار های بالا میتونیم نتیجه بگیریم که با گذاشتن یه دستهبند خطی بر روی خروجی شبکه عصبی میشه نتایج پیشبینی رو بهتر کرد. کاری که در آینده به عنوان بهبود میشه روی مدل فعلی پیاده کرد. البته همین دو ویژگی رو به عنوان ورودی در شبکه عصبی داشتیم ولی احتمالا به خاطر کمبود داده، مدل نتونسته اهمیت بیشتری رو به این دو ویژگی بده. این شهود میتونه ما رو به معماریهای بهتری هم رهنمون کنه! مثلا ممکنه یه شبکه CNN بتونه اهمیت این ویژگیها رو استخراج کنه.
اما سوال اصلی اینه که مقدار precision تا کجا میتونه بهتر بشه؟ برای جواب دادن به این سوال باید بدونیم از منظر مصالحه bias-variance میزان unavoidable-bias چقدر هست. این میزان خطا در واقع مشخص میکنه که حتی یه دستهبند بهینه تا چه حد میتونه به دقت خوبی برسه. مثلا تصور کنین که دو تا دیتا در یک فضا کاملا روی هم افتاده باشن و یکیشون مربوط به دسته اول و دیگری مربوط به دسته دوم باشن. در این حالت هیچ مدلی نمیتونه تفاوت این دو دیتا رو بفهمه. حالا اگه این دو دیتا خیلی به هم نزدیک باشن شانس پیدا شدن کرنلی که بتونه این دیتا ها رو توی فضای دیگه ببره و این دیتاها از هم کامل دور باشن باز هم پایین میاد. به عبارت دیگه شبکه عصبی ( که لایههای خودش میتونه به عنوان کرنل فانکشن در نظر گرفته بشه ) با دادههای ناکافی، به احتمال بسیار بالا نمیتونه اون کرنل رو پیدا کنه. حالا ما میخوایم یه تحلیل احتمالا تقریبا درست ارایه بدیم که میزان خطا در precision از چه حدی نمیتونه پایینتر باشه.
برای این کار ابتدا از هر دو دسته ریزش کرده و ریزش نکرده ۲۵۰۰۰ داده رو به صورت تصادفی بر میداریم. بعد فاصله دو به دوی هر یک از دیتاهای دسته اول رو با دسته دوم محاسبه میکنیم. حالا باید ببینیم چند تا داده ریزش نکرده وجود داره که در همسایگی اپسیلون اون حداقل یه داده ریزش کرده هست.

با توجه به تصویر بالا و اینکه مدل ما به recall حدود ۷۰ درصد رسیده پس میتونیم فرض کنیم که فاصلههای بیشتر از ۰.۰۷ در مدل ما تشخیص داده شده اما در این حالت حدود ۶ درصد دادههای ریزش نکرده در همسایگیشون به فاصله کمتر از ۰.۰۷ یه داده ریزش کرده هست. پس در حالت اپتیمال مقدار FPR یا false positive rate میتونه حدود ۶ درصد باشه. با توجه به نسبت دادههای ریزش کرده و ریزش نکرده ( که حدود یک به شش هست) مقدار precision در حالت اپتیمال حدود ۶۵ درصد خواهد بود. پس دستهبند بهینه در بهترین حالت میتونه به precision حدود ۶۵ درصد برسه. این به خاطر درهمرفتگی دیتاهای موجود با توجه به فضای ویژگی هست که تشکیل دادیم.
جمعبندی
در تحلیل بالا ابتدا دادگان رو بررسی کردیم و بعد یه تعریف از ریزش ارایه دادیم. بعدش هم سعی کردیم از روی دیتای تراکنشها الگوهای رفتاری خرید مشتریان رو در بیاریم. کیفیت مدل ارایه شده عالی نبود اما با توجه به تحلیل خطا قابل قبول بود. برای ارزیابی مدل معیار AUC رو معرفی کردیم که باعث میشه با تغییر حدآستانه تابع خروجی sigmoid بتونیم یه مصالحهای بین مقدار recall و false positive rate بهدست بیاریم. نشون دادیم که توی فضای ویژگی که ترسیم کردیم درهمرفتگی زیادی وجود داره که مقدار unavoidable bias رو بررسی کردیم. یه نکتهای که لازمه بهش اشاره بشه اینه که ما از روی داده تراکنشها به فضای ویژگی جدید رسیدیم و این به خاطر محدودیت مدل بود که نمیتونه وابستگیهای زمانی رو به خاطر بسپره. به همین دلیل ما مجبور بودیم فاز مهندسی ویژگی داشته باشیم و ویژگیهایی که در بالا توضیح دادیم رو از روی داده به دست بیاریم. همونطور که دیدیم فضای ویژگیای که ترسیم کردیم درهمرفتگی زیادی داشت که موجب میشد unavoidable bias افزایش پیدا کنه. یه فاز بهبود میتونه این باشه ، به جای استفاده از شبکه عصبی feed forward از شبکه LSTM استفاده کنیم و دادههای تراکنش رو به صورت مستقیم به شبکه بدیم و خود شبکه بهترین فضای ویژگی رو پیدا میکرد. البته این روش نیاز به دادههای بیشتری نسبت به روش فعلی داره ولی میتونه تست بشه. مورد دیگهای که باز به عنوان بهبود میتونستیم استفاده کنیم این بود که دادههای مشتریان رو قبل از انجام تحلیل خوشهبندی میکردیم و برای هر خوشه یه مدل جداگونه ترین میکردیم چرا که نحوه ریزش توی خوشههای متفاوت مشتریان میتونه متفاوت باشه و در تحلیل بالا یه فرض سادهسازی ضمنی گرفته شده که مشتریان خوشههای مختلف با توزیع یکسان دچار ریزش میشن. انشاالله در آیندهای نه چندان دور به سراغ این ایدهها خواهیم رفت....
منابع
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- Principle Component Analysis
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- Receiver operating characteristic (ROC)
- Understanding the Bias-Variance Tradeoff
مطلبی دیگر از این انتشارات
بهبود کیفیت در توسعهی نرمافزار، از حرف تا عمل
مطلبی دیگر از این انتشارات
بله گرفتن از خود!
مطلبی دیگر از این انتشارات
ایدهای جسورانه برای بالا نگهداشتن سرویس! - قسمت اول